In this project, I built an end-to-end Retrieval-Augmented Generation (RAG) system that allows users to ask natural-language questions about iOS 18 features, with answers grounded strictly in official Apple documentation.
The system uses n8n for orchestration, Pinecone for vector storage, and OpenAI for embeddings and response generation, and is deployed with a public chat interface.
🔗 Project Links
- GitHub Repository: https://github.com/seyyednavid/ios18-rag-agent
Table of Contents
- 00. Project Overview
- 01. Data Overview
- 02. RAG Architecture
- 03. Document Ingestion Pipeline
- 04. Query & Retrieval Pipeline
- 05. Application & Example Queries
- 06. Growth & Next Steps
00. Project Overview
Context
Large Language Models are powerful, but their knowledge is static and prone to hallucination when answering questions about newly released or domain-specific content.
With the release of iOS 18, users need a reliable way to query official feature documentation without relying on incomplete or outdated model knowledge.
The goal of this project was to build a document-grounded AI agent that answers questions about iOS 18 only using verified source material.
Actions
I designed and implemented a full RAG pipeline that:
- Ingests official iOS 18 documentation (PDF)
- Splits content into semantically meaningful chunks
- Generates dense vector embeddings
- Stores embeddings in Pinecone
- Retrieves only relevant chunks at query time
- Generates grounded answers via an AI agent
- Exposes a public chat interface using n8n
All orchestration, retrieval, and generation logic is handled visually and programmatically inside n8n workflows.
Results
The final system:
- Answers questions strictly based on the source document
- Prevents hallucinations by rejecting unsupported queries
- Returns concise, accurate feature explanations
- Supports public access via a hosted chat UI
- Demonstrates a production-style RAG architecture without custom backend code
Growth / Next Steps
Potential future enhancements include:
- Source citation per response
- Multi-document ingestion and namespace separation
- Authentication and rate limiting for public chat
- Streaming responses for improved UX
- Automatic document re-indexing on file updates
01. Data Overview
The knowledge base consists of an official Apple PDF:
- iOS 18 – All New Features (September 2024)
This document serves as the single source of truth for the system.
It is ingested once, chunked, embedded, and persisted in a vector database, allowing efficient semantic retrieval at query time.
02. RAG Architecture
The system follows a classic Retrieval-Augmented Generation architecture:
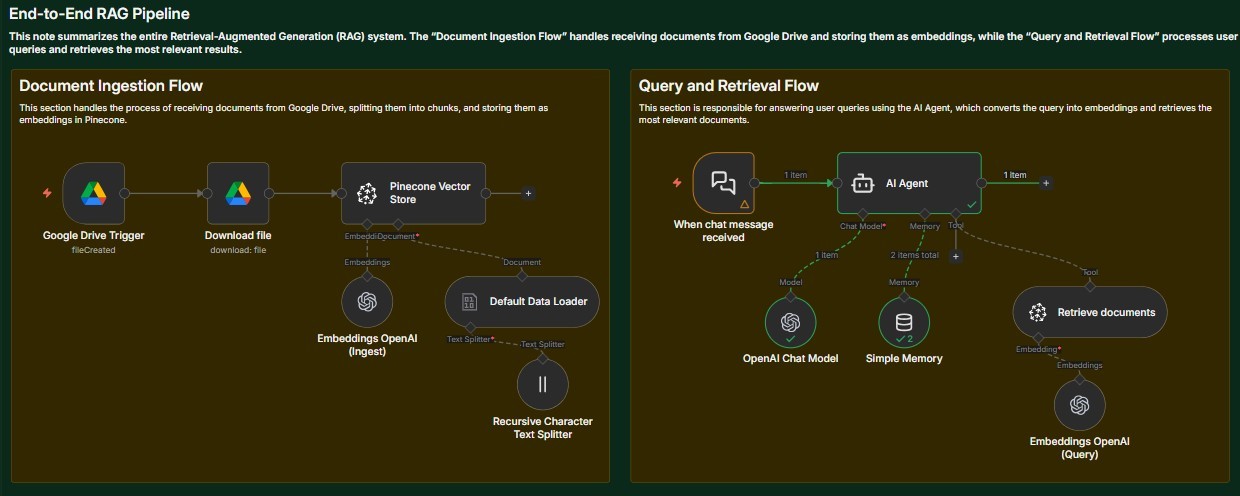
At a high level:
- Documents are ingested and vectorised
- User queries are embedded
- Relevant chunks are retrieved from Pinecone
- Retrieved context is injected into the AI agent prompt
- The model generates a grounded answer
03. Document Ingestion Pipeline
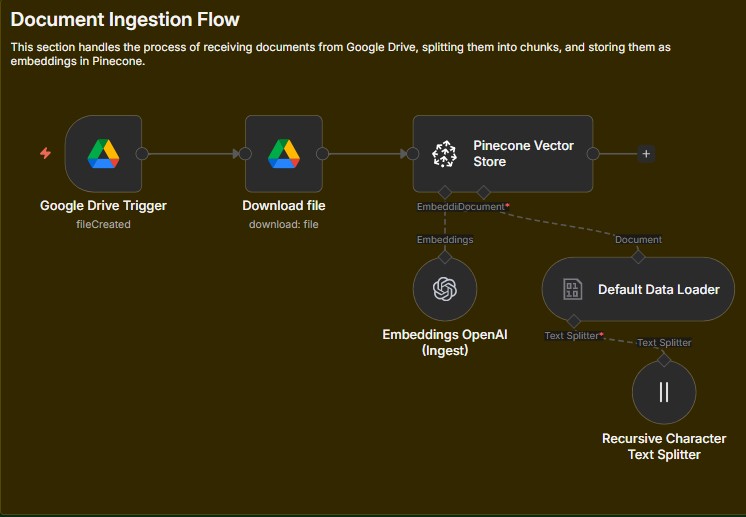
The ingestion workflow includes:
- PDF loading
- Recursive text chunking
- Embedding generation using OpenAI
- Vector storage in Pinecone
This process ensures high-quality semantic retrieval while keeping token usage efficient.
04. Query & Retrieval Pipeline
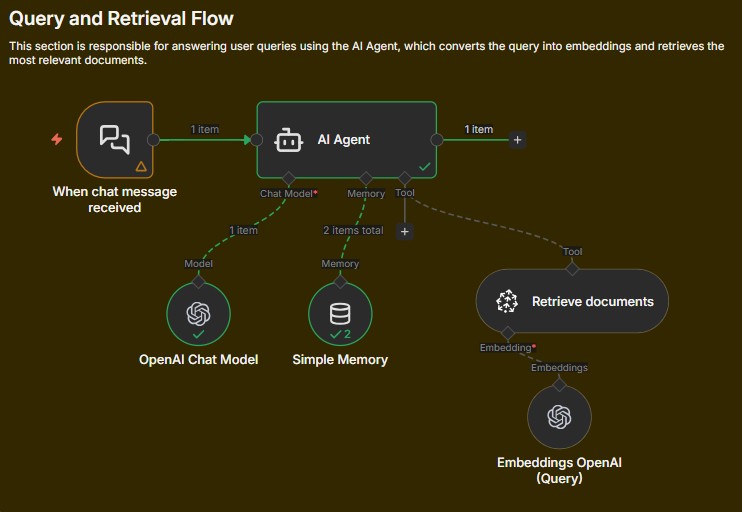
At query time:
- A chat trigger receives the user question
- The query is embedded
- Pinecone retrieves the most relevant chunks
- The AI agent generates a response using only retrieved context
If no relevant context is found, the agent safely declines to answer.
05. Application & Example Queries
The system is exposed through a public n8n-hosted chat interface:
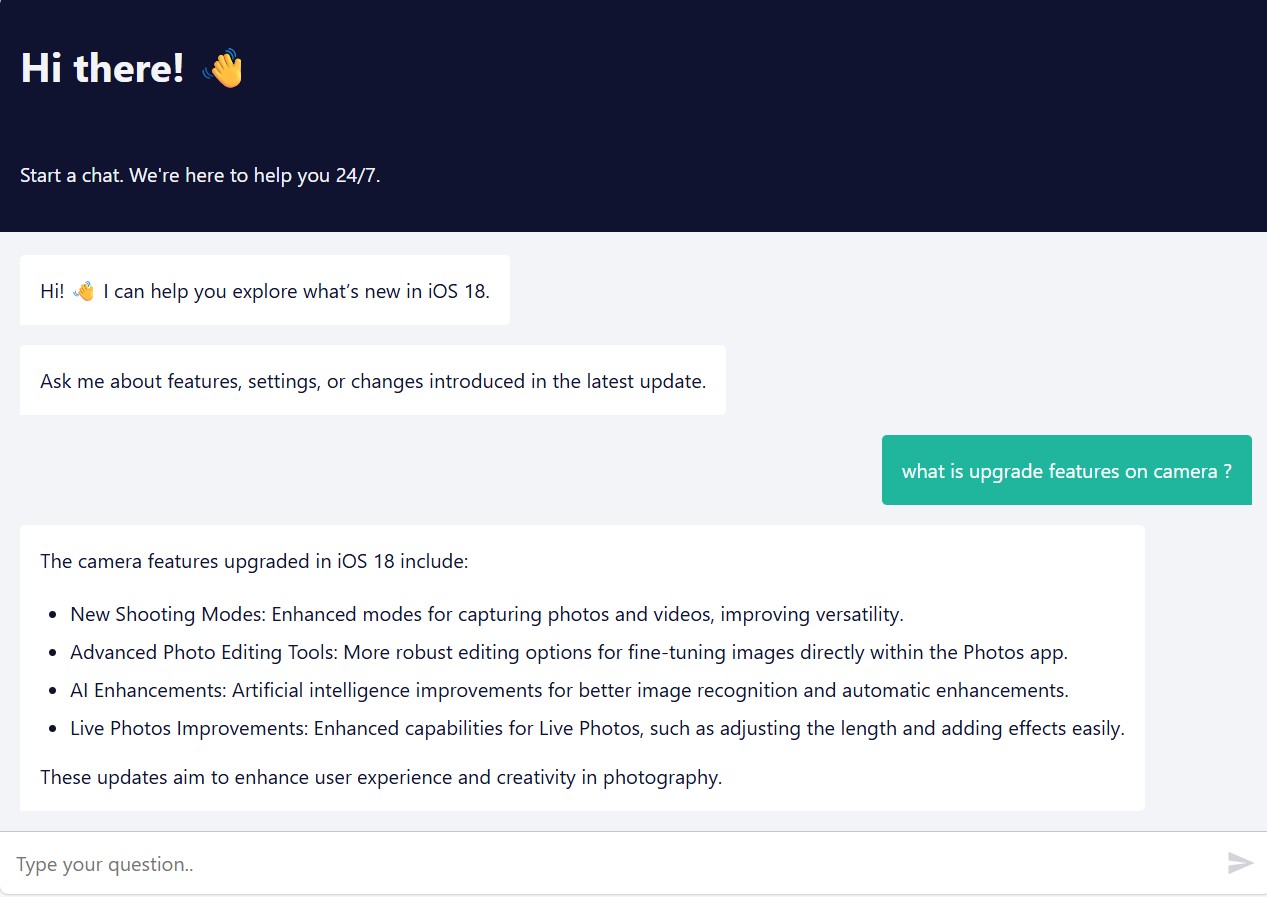
Example query:
What new camera features are introduced in iOS 18?
The agent retrieves relevant sections from the documentation and produces a grounded, document-based response.
Unsupported questions are rejected with a clear fallback message.
06. Growth & Next Steps
This project forms a strong foundation for:
- Documentation chatbots
- Product support assistants
- Internal knowledge bases
- No-code / low-code AI systems
Future work could extend this into a multi-document, multi-product RAG platform with richer UI and analytics.